Token-and-Duration Transducers (TDT) are a recent contribution to the space of sequence transductions models by Nvidia. By building upon RNNT to enable joint token-duration prediction, TDT emits both a token and its associated duration - revealing the number of input frames we can safely skip. This innovation resolves two challenges facing prior sequence transduction models:
- Explicit segmentation: Learns frame-token alignments without auxiliary objectives
- Efficient inference: Enables frame skipping during decoding, reducing redundant computations
This frame skipping alleviates the auto-regressive decoding bottleneck present in RNNT networks.
Architecture
TDT enhances the RNN-T architecture for joint token and duration prediction. It expands the RNN-T joint network’s output dimension beyond the vocabulary size and partitions this output. One partition handles label representations, the other handles duration representations. Separate softmax layers are applied to each partition’s output (see diagram below) to generate label and duration probabilities [@xuEfficientSequenceTransduction2023].
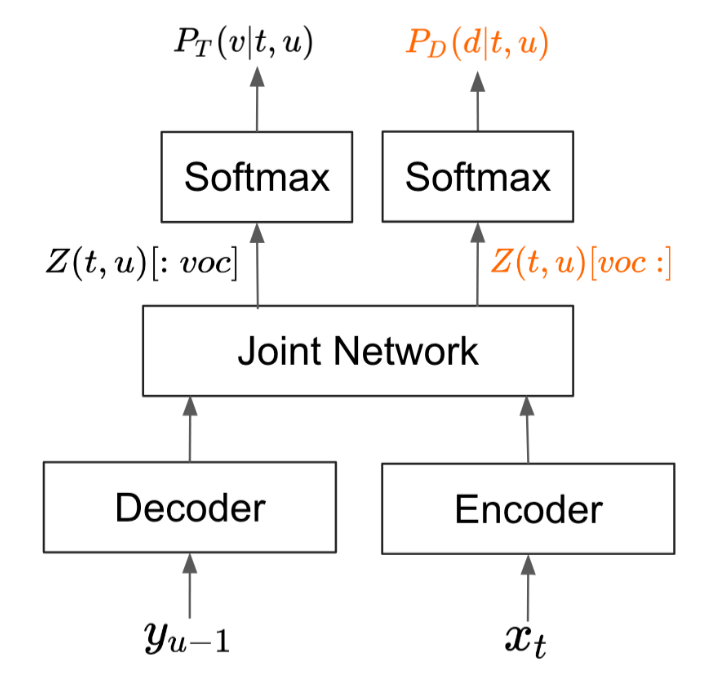
This enables simultaneous learning and emission of both tokens and their duration.
Training
Training follows the RNNT/CTC paradigm of marginalizing over alignments, but with duration () and label () augmented alignments:
We assume the labels and durations to be conditionally independent:
this allows us to compute the problem efficiently with the modified forward-backward algorithm derived by Xu et al. [@xuEfficientSequenceTransduction2023]
Thus, we can also perform maximum likelihood training for RNNT, by minimizing the loss as defined BELOW,
Inference
It is at inference time we can make use of the emitted duration to skip redundant input frames, but in practice, we wish to perform batched inference, but it is not simple to parallelize TDT models. Parallel computation is most efficient when running in lock-step, but we cannot be guaranteed that the tokens emitted for different samples across a batch, also have the same duration - so the frame-skipping prevents us computing in lock-step.
We could choose to only skip frames, where is the shortest duration across the batch, but in practice this causes a significant increase in insertion errors. However, this can be remedied by combining the TDT and RNNT loss with a sampling probability :