Just like Connectionist Temporal Classification resolved issues faced by RNNs, RNN Transducers further improve upon CTC by removing some of its limitations. More specifically:
- CTCs make some obvious decoding mistakes due to assumption of conditional independence of the labels through time.
- E.g. in a speech-to-text scenario, CTC may deem “He one the game” more probable than “He won the game” since it is indifferent to context.
- CTCs require the output sequence length to be less than the input sequence length.
- This precludes CTC models from being used for whole classes of problems, such as text-to-speech. In 2012 Graves introduced Recurrent Neural Network Transducers (RNNT), a generalization of HMM and CTC models that addresses some of their shortcomings. [@gravesSequenceTransductionRecurrent2012]
Architecture
RNNT resolves CTCs problems by slightly modifying and extending its architecture. To deal with the sequence length restriction, RNNTs allow for producing multiple outputs per input. Furthermore, in addition to the CTC encoder, denoted here as the transcription network, , it adds a language model, dubbed the prediction network, , and a simple feed forward network passed into a softmax function, the joiner. All this enables to model to take context into account. [@gravesSpeechRecognitionDeep2013]
See image BELOW [@lugoschSequencetosequenceLearningTransducers2020]
![]()
This allows us to have the capabilities of CTC, but simultaneously consider semantic meaning via the language model, allowing the joiner to wholistically predict the token by considering both the underlying sequence data, and which outputs would make sense in its context.
Training
Jointly modelling over both input and output sequence length is what allows the decoupling of the two lengths, and thus the removal of the CTC sequence length restriction. Due to the introduction of a language model, we no longer consider the redundancy in terms of repeated symbols from CTC. This means that for each output sequence, e.g. , we can model each alignment, e.g. , as a path from the top-left to the bottom-right in a grid as seen on image BELOW. [@lugoschSequencetosequenceLearningTransducers2020]
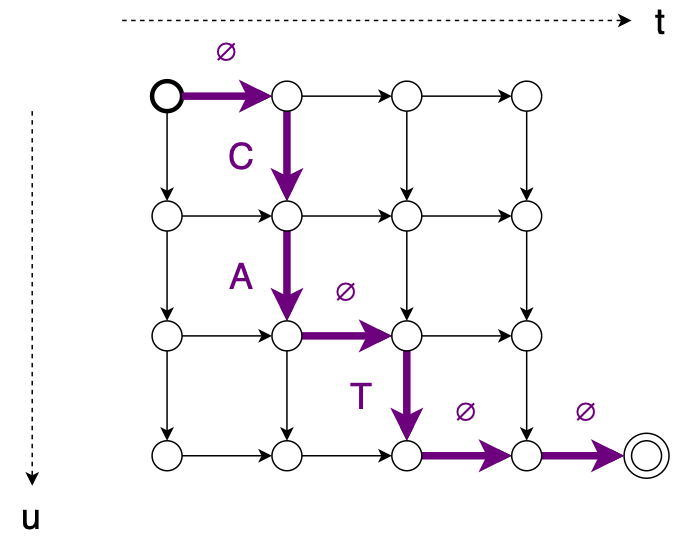
It also alters the way in which we calculate the objective function, the principle of it is the same as in the CTC Training section, where we marginalize over all possible alignments
where each alignment, , is decomposed into triples, , each corresponding to a label, , and coordinate, , in the grid ABOVE.
And again, due to the size of , the naive approach to calculate this is intractable, but can be solved using a modified forward-backward algorithm to take advantage of path merging. [@gravesSequenceTransductionRecurrent2012]
Thus, we can also perform maximum likelihood training for RNNT, by minimizing the loss as defined BELOW,