While RNNTs and CTCs focus on sequence transduction with explicit alignment mechanisms, Transformers represent a fundamentally different approach to sequence modeling. Introduced by Vaswani et al. in 2017 [@vaswaniAttentionAllYou2017], transformers rely entirely on attention mechanisms rather than recurrence or explicit alignment.
What makes transformers stand out is their ability to process all tokens in parallel while capturing global dependencies across the entire sequence. This enables the embedding of “cat” in “feed my cat” and “get a cat scan” to accurately capture the contextual meaning without ambiguity.
FIXME: Move the last paragraph The amount of tokens used for context is called the context-size of the model.
Attention Mechanism
The novel contribution of transformers is the self-attention mechanism, which can be mathematically formulated as:
Where , , and represent query, key, and value matrices derived from the input embeddings, and is the dimensionality of the key vectors.
Self-Attention Head
The attention mechanism is what enables transformers to augment embeddings with contextual meaning. After the word embedding step, a word will have a specific embedding regardless of the contextual meaning. To enrich the embedding with contextual meaning, Vaswani et al. take inspiration from retrieval systems and learn three projections onto different subspaces:
- Query (): Represents what information the token needs from the context
- Key (): Represents what information a token can provide to others
- Value (): Contains the actual content information to be aggregated
These projections are created by multiplying the input embeddings with learned weight matrices (, , ). The model then calculates attention scores by taking the dot product between queries and keys, which determines how much each token should attend to every other token by way of directional similarity. By updating the query and key matrices through training with large amounts of data, the model encodes in them a notion of relevance that can effectively determine which contexts are important for each token.
The attention scores are then normalized using the softmax function and used to create a weighted sum of the value vectors, putting this together, we get the mathematical formulation for a single self-attention head:
where the scaling factor is present to provide numerical stability, see a graphical representation BELOW [@vaswaniAttentionAllYou2017].
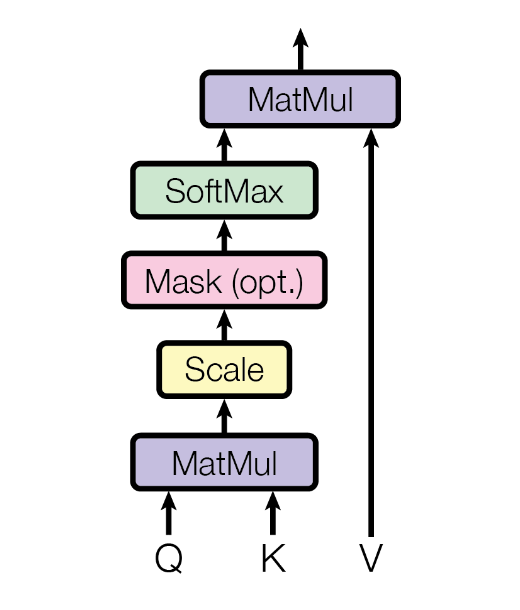
This process allows each token’s representation to be updated with information from other relevant tokens in the sequence, creating context-aware embeddings that capture the appropriate meaning based on surrounding words.
TODO: Is relevant or no?
Cross-Attention Head
Allows for multimodality, with the K/Q maps operating on different datasets, say a sentence in different languages to allow the learning of a translation mapping.
Multi-headed Attention
Multi-headed attention extends the basic attention mechanism by running multiple attention heads in parallel, each with its own learned parameter sets. This approach allows the model to simultaneously attend to information from different representation subspaces, and thus to learn several distinct ways in which context can update the embedding of a token. Mathematically, multi-headed attention is defined as:
where each head is computed as:
where in the case of self-attention. See graphical representation BELOW. Modified formula from stackexchange
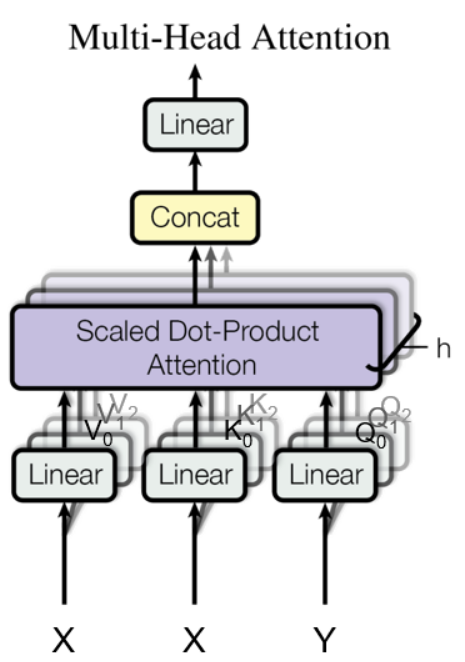
The attention head concatenation followed by linear projection with serves two critical functions:
- It reshapes the concatenated representations back to the model’s required dimension.
- It learns optimal combinations of the distinct contextual information extracted by each attention head.
This learned transformation enables the model to integrate information from multiple representational subspaces into a unified, context-rich embedding.
Each attention head can learn to focus on different aspects of the input sequence – some heads might capture syntactic relationships, while others focus on semantic connections or positional patterns. This parallel processing of multiple relationship patterns enables a much richer contextual representation than a single attention head could provide.
Positional Encoding
Positioning is crucial in language and any other domain where order matters, so capturing positional patterns is indeed desirable for attention mechanisms, as briefly mentioned in the section on Multi-headed Attention.
However, the transformer architecture as described thus far lacks an inherent mechanism to associate tokens with their positions in a sequence. The attention mechanism alone is permutation-invariant, meaning it treats input tokens as an unordered set.
To address this limitation, Vaswani et al. introduced an elegant positional encoding scheme using trigonometric functions. These encodings generate unique vectors for each position, which are then added to the input embeddings before they enter the transformer. This effectively “embeds” positional information into the token representations [@vaswaniAttentionAllYou2017].
Architecture
The transformer architecture stacks alternating attention and feed-forward (linear) blocks in multiple layers, see BELOW.
![]() As information flows through this structure, embeddings progressively refine from capturing simple patterns in early layers to representing complex abstractions in deeper layers, enabling the model to build a sophisticated hierarchical understanding of the input.
As information flows through this structure, embeddings progressively refine from capturing simple patterns in early layers to representing complex abstractions in deeper layers, enabling the model to build a sophisticated hierarchical understanding of the input.