Recurrent Neural Networks (RNNs) have long been a go-to model for predicting label sequences from noisy input data. However, RNNs face two significant shortcomings:
- They require the input data to be pre-segmented.
- For instance, in an audio transcription task, it would need knowledge of which segment of the input sequence corresponds to which word, and additionally.
- Post processing is required to remove redundant labels in the output. In 2006 Graves et al introduced the Connectionist Temporal Classification (CTC) technique, which resolves these shortcomings. @gravesConnectionistTemporalClassification2006
Alignment
Imagine as a base model, we have an RNN that produces the most likely label at each time-step. We may have different waveforms, , that all correspond to the same label, . Depending on pronunciation, the RNN may (correctly) decode these different waveforms to alignments looking like “ccaaaat”, “caatttt” etc. To handle this redundancy of repeated labels, CTC simply collapses repeated tokens, see figure below @hannunSequenceModelingCTC2017.

This fails to account for cases where repeated tokens are intended, such as for words like “hello”, to account for this, a blank token is introduced, let us denote it as . This allows the model to assign a placeholder token for periods of silence, or when otherwise deemed necessary as a separator. This allows the collapsing post processing to handle repeated entries by first merging repeated characters, and subsequently removing the blank tokens, see figure below @hannunSequenceModelingCTC2017.

This means, that after preprocessing, all alignments now should correspond to the label .
Now that we have introduced the concept of alignments, let us define them more formally: Denote by the input space, and by all sequences over the input space. Similarly, let denote the output (label) space, and all sequences over the output space. We extend the output space with the blank symbol introduced previously .
We can now define out earlier collapsing procedure as a many-to-one map , where the subscript denotes the sequence length that the alignment must map to a sequence of equal or shorter length. The inverse map, , then denotes the set of all alignments for some label sequence, .
Training
For CTC training, the objective for an pair is , we can obtain this probability by marginalizing over all possible alignments for and further rewrite by assuming network outputs to be conditionally independent in time:
where alignment is decomposed into pairs of corresponding label and timestep, .
These objective scores can’t easily be calculated naively in the manner suggested by equation ABOVE, assume has no repeat symbols, and that , , then . So we face the issue that may explode combinatorically.
Fortunately, by realizing that alignments reaching the same output at the same step can be merged, we can use dynamic programming to move forward, see image BELOW [@hannunSequenceModelingCTC2017] .
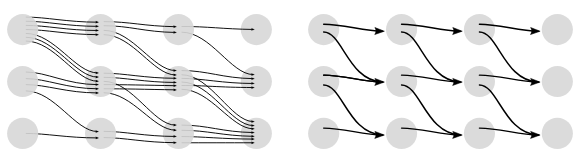
These probabilities can be calculated efficiently using a modified version of the well known forward-backward algorithm to avoid calculating probabilities for each alignment individually, but rather across all alignments simultaneously. @gravesConnectionistTemporalClassification2006 Note, the specific expression for how to calculate the probabilities are in terms of the forward backward algorithm, and will not be discussed further here.
The CTC objective in equation ABOVE can then be used to perform maximum likelihood training, i.e. simultaneously maximizing the probabilities of attaining of correct classifications over the training set, or equivalently, minimizing the negative log-likelihood, seen here as the loss function
Inference
At inference time we would like to find the most likely label sequence given our input sequence, i.e. we wish to solve
However, we currently have no algorithms that make this optimization problem tractable. So we shall settle for a heuristic. Several decent heuristics exist, such as best path decoding, prefix search decoding, and beam search, each with their own virtues and drawbacks. However, upon further development of CTCs successor, RNNT, Beam search has been deemed the superior for both CTC and RNNT. [@gravesSpeechRecognitionDeep2013]